Data wrangling has become the primary process to remain competitive for organizations. Data is the backbone of the digital age, and with growing volume leading to data explosion, the need for effective data handling becomes paramount. Among the essential processes in the realm of data science is Data Wrangling. This article delves into the intricacies of Data Wrangling, exploring what it is, how it works, the importance of this process and also provides a step-by-step guide for enthusiasts to master this crucial skill.
What is Data Wrangling?
Data Wrangling, also known as Data Munging, is the process of transforming and mapping the raw data into a more usable and structured format that is fit for analysis. This involves cleaning, structuring, and enriching the raw data into a format that can be easily consumed by analytical tools and algorithms. It may be thought of as the pre-processing phase where the dataset is being prepared for further analysis.
How Does Data Wrangling Work?
Data Wrangling encompasses several tasks that collectively contribute to the preparation of data for analysis. Some key aspects include:
- Data Collection: This step involves gathering raw data from various sources, including databases, spreadsheets and external APIs.
- Data Cleaning: Data Cleaning is basically identification and handling of missing or inaccurate data points to ensure data accuracy.
- Data Transformation: Conversion of data into a standardized format, addressing inconsistencies and ensuring uniformity.
- Data Enrichment: Augmenting the dataset with additional information to enhance its depth and relevance.
- Handling Outliers: This is a very important step: identifying and addressing outliers. Outliers, if not treated properly could skew analytical results.
- Data Integration: Combining data from different sources to create a unified dataset for analysis.
Data Wrangling & Data Cleaning: Are they same?
Sometimes used interchangeably, data cleaning and data wrangling serve different purposes. Data cleaning is actually a vital step within wrangling which involves scrubbing off inaccuracies and inconsistencies. Data wrangling on the other hand is the broader set which involves shaping the raw data into a usable form.
How To Do Data Wrangling? – A Step-by-Step Guide:
Raw data is like a messy kitchen cabinet: full of potential, but unusable until you properly organize it. Data wrangling is similar to your culinary skill, transforming the chaos into valuable insights. Here’s your roadmap:
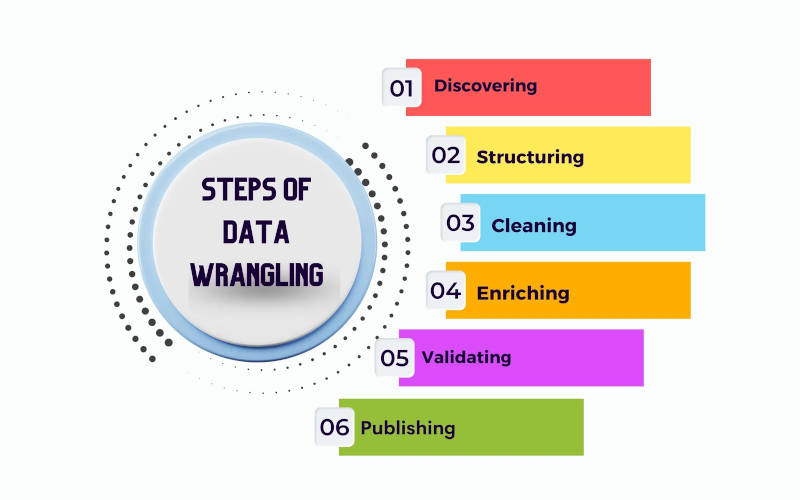
- Discovering: Dig in and understand your data. Whether there are any missing ingredients (data points)? Spot any glaring issues like wilted veggies (errors)? This preps you for the cooking ahead.
- Structuring: Raw data is like messy potatoes – unappealing and tough to work with. Structuring them cleans and shapes it, making them ready for analysis. Think of chopping, peeling, and maybe mashing (depending on your recipe, aka analysis type).
- Cleaning: Get rid of rotten bits! Data cleaning removes errors that could skew the whole output and interpret something totally different. Imagine removing moldy potatoes – you wouldn’t want them messing up your dish, right?
- Enriching: Do you have all the ingredients you need? Sometimes, enriching your data with additional sources can add flavour and depth to your analysis. Just like adding herbs and spices, it can be powerful, but it needs to be used thoughtfully.
- Validating: Before serving, double-check everything. Data validation helps in ensuring consistency and quality. Think of it as tasting your dish before presentation – you wouldn’t want to serve raw data, would you?
- Publishing: Ready to share your culinary triumph? Publishing your data makes it available for others to analyze and enjoy. Think plating and presentation – choose a format that’s clear and appetizing for your audience.
Remember: Wrangling data takes practice, but with these steps, you can turn chaos into insights!
Need for Data Wrangling Automation
- Time Efficiency: Data wrangling can be a tedious task, especially when dealing with large datasets. Here automation comes to play. It helps in not only streamlining the process, reducing manual effort, but also speeding up the overall analysis.
- Consistency and Accuracy: Automated tools ensure consistency in data processing, reducing the likelihood of human errors. This is crucial for maintaining data accuracy and reliability throughout the analysis.
- Scalability: With growing volume and complexity of data, manual data wrangling becomes quite impractical. Automation allows for scalability, enabling data scientists to handle more extensive datasets efficiently.
- Reproducibility: Automated workflows are easily reproducible. This ensures that the same steps can be applied consistently to different datasets. This helps to maintain the integrity of analysis and facilitate collaboration.
You may also read : Data Quality Management and Control
Essential and Best Data Wrangling Tools
- Pandas: Pandas is an extremely powerful Python library widely used for data manipulation and analysis. It provides data structures like DataFrame for efficient data wrangling tasks. Its versatility and extensive documentation make it a favorite among data scientists.
- OpenRefine: OpenRefine, formerly Google Refine, is an open-source tool which specializes in cleaning and transforming messy data. It has a user-friendly interface, and makes it accessible for those who may not have extensive programming skills. OpenRefine is helpful when it comes to handling data quality issues and standardizing formats.
- Trifacta: Trifacta is a cloud-based data wrangling tool that leverages machine learning algorithms to suggest and automate data cleaning operations. Its intuitive interface allows users to visually explore, clean, and transform data without extensive coding.
- DataWrangler: Developed by Stanford University, DataWrangler is an interactive web-based tool which helps in cleaning and exploring datasets. It helps in simplifying the process of transforming raw data into a structured format through a series of user-guided steps.
- Apache Spark: Apache Spark, along with its Spark SQL and DataFrame APIs, is a distributed computing framework that can facilitate scalable data processing. It is particularly useful for handling large datasets and complex transformations, making it a popular choice for big data analytics.
Cases of Data Wrangling in Various Industries
| Banking | It helps financial institutions access and manage quality data to measure, manage and Monitor Risk for ongoing credit, market and operational risk management needs. |
| Healthcare | It helps healthcare and pharma companies speed research and development, accelerate drug discovery and deliver breakthrough therapies faster. |
| Manufacturing | It helps drive Supply Chain optimization, Asset Management and Operational Intelligence. |
| Insurance | Helps improve areas like Risk Management and Underwriting. |
| Public sector | Helps improve Cybersecurity, improving Citizen Experience and Case Management. |
Conclusion:
Data Wrangling is a critical step in the data science pipeline, ensuring that data is refined and prepared for meaningful analysis. As technology takes more and more steps towards the future, Data Wrangling holds promises of automation, artificial intelligence, and more efficient tools to streamline the process. Thus, for data science enthusiasts, mastering the art of Data Wrangling can open doors to unlocking much valuable insights from the ever-growing sea of data.